


If you've ever used a serverless platform and felt that occasional "why did that request suddenly feel slow?" moment, you've brushed up against cold starts. Cloudflare recently shared how it cut Workers cold start delays by roughly 10x, not by shaving milliseconds off compilation, but by making cold starts happen far less often in the first place. The trick is something called worker sharding.
This article walks through the idea, why the old approach stopped working, and how Cloudflare redesigned request routing to keep Workers warm more reliably.
What A Cold Start Actually Means For Workers
A cold start happens when a server doesn't already have your code running in memory, so it has to fully "spin up" the serverless workload before it can answer the request.
For Cloudflare Workers, that startup has four main steps:
• Compile it into something the CPU can execute
• Run any top-level initialization code (the stuff that runs on import)
• Finally, call the request handler for the actual incoming request
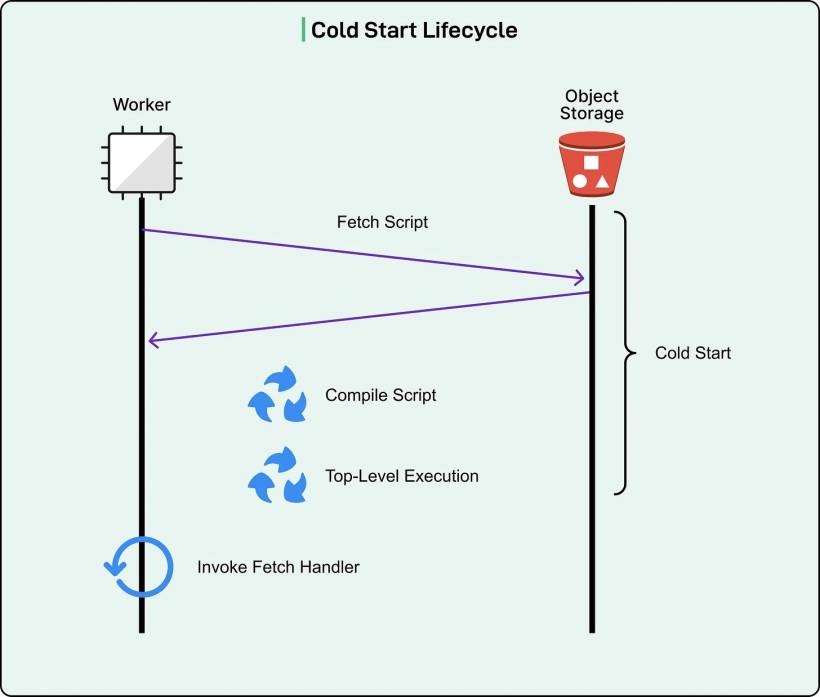
That sequence matters because only the last step produces a response. Everything before it is pure waiting from the user's point of view.
The big headline improvement is that Cloudflare says 99.99% of requests now land on already-running instances, meaning only a tiny fraction of requests ever pay the "startup tax."
The First Fix: Hiding Cold Starts Behind TLS Handshakes
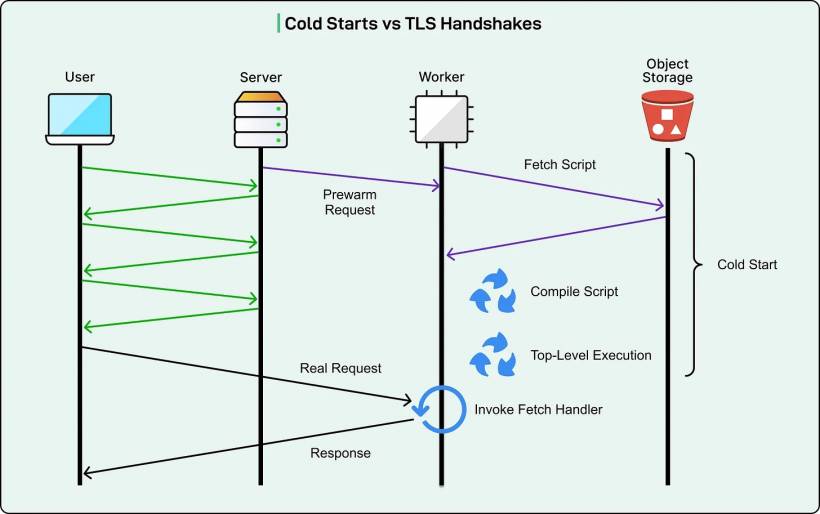
Back in 2020, Cloudflare had a clever workaround: hide the startup time during the TLS handshake.
TLS is the encryption setup phase for HTTPS. Before any real request data is exchanged, the client and server perform a handshake that takes multiple back-and-forth round trips. That handshake delay created a window where Cloudflare could quietly start a Worker "in the background."
And they had a key advantage: the very first TLS message includes the SNI field (Server Name Indication), which reveals the hostname the user is trying to reach. With that hostname, Cloudflare could guess which Worker would be needed and start warming it immediately.
This worked well when cold starts were short and TLS handshakes were relatively long. In the best case, the Worker finished starting before the handshake completed, so the user didn't feel the cold start at all.
Why That Trick Stopped Working
Over time, the timing relationship flipped.
Cold starts got longer
Cloudflare raised script size limits (allowing much bigger deployments) and increased the CPU time allowed during startup. Bigger code takes longer to fetch and compile. More startup CPU budget means initialization can do more work, which can also extend the cold start.
TLS 1.3 reduced handshake overhead compared to TLS 1.2, shrinking the "free hiding time" Cloudflare used for prewarming.
Put those together and the illusion broke. The handshake no longer provided enough time to cover the full startup cost, so users started to feel delays again.
The Real Insight: Don't Fight Cold Starts, Reduce How Often They Happen
At some point, optimizing compilation and fetch times becomes a game of diminishing returns. Cloudflare's shift in thinking was: instead of trying to make every cold start faster, reduce the number of cold starts across the network.
The root cause wasn't just "Workers are slow to start." It was "Workers are getting started too often because requests are spread too thin."
Here's the classic example:
That's how a low-traffic app can end up with an almost constant cold-start feeling, even though it's not "down" and it's not "broken."
Worker Sharding: Keep Each Worker "At Home" Inside A Data Center
Worker sharding changes the routing model inside a data center:
This does two things at once:
Memory efficiency improves because you don't need 300 servers each holding a copy of a Worker that only runs once every few hours.
In other words, the system stops wasting memory on duplicates and uses that memory to keep more Workers warm overall.
Why A Consistent Hash Ring Matters
If you're going to give each Worker a home server, you need a mapping strategy that doesn't fall apart every time servers come and go.
A naive hash table approach breaks badly when the server pool changes. Add or remove a server and suddenly lots of Workers get remapped, causing a wave of cold starts because everyone "moves house" at the same time.
A consistent hash ring avoids that.
The basic idea:
• Hash each Worker to a position on the same ring
• For a Worker, walk clockwise and pick the first server you hit
When a server disappears, only the Workers that mapped to that server need to move. When a server is added, only a slice of Workers shift over. Most Workers keep the same home server, which is exactly what you want if the goal is to stay warm.
What Happens When A Request Hits The "Wrong" Server
With sharding, the server that first receives the request isn't always the home server for that Worker.
So Cloudflare treats servers in two roles:
Shard server: the Worker's home server according to the hash ring
If the shard client is also the home server, great, it runs the Worker locally. If not, it forwards the request internally to the shard server.
Yes, forwarding adds latency (about a millisecond). But that's tiny compared to a cold start that can take hundreds of milliseconds. In practice, a warm Worker plus a short internal hop wins.
Avoiding Overload Without Throwing Errors
Sharding concentrates traffic, so there's a risk: what if a Worker's home server gets overloaded?
Cloudflare considered a "permission first" approach where the shard client asks before sending the request, but that adds an extra network round trip on every sharded request.
Instead, it chose an optimistic approach:
If the shard server is overloaded, it bounces the request back to the shard client, which then runs the Worker locally.
Because overload refusals are rare, it's better to optimize the common case rather than punish every request with extra chatter.
Why Cap'n Proto RPC Helps In The Messy Edge Cases
Cloudflare uses Cap'n Proto RPC to connect servers. This matters because it lets them pass around "capabilities," which are basically handles to services or objects that can be invoked later.
The clever part: the shard client can include a "lazy Worker capability" that represents a Worker instance that hasn't started yet on the shard client.
If the shard server refuses due to overload, it can return that lazy capability back. When the client then invokes it, the system realizes it's pointing to a local instance and short-circuits, avoiding pointless back-and-forth and preventing wasted bandwidth on large request bodies.
Nested Worker Calls: Making Sharding Work For Real-World Products
Cloudflare's ecosystem isn't just "one Worker per request." Workers can call other Workers through service bindings, KV-related flows, and especially Workers for Platforms where multiple Workers may participate in a single request pipeline.
Sharding makes this harder because execution context now needs to travel across servers: permissions, limits, feature flags, logging, and tracing setup.
Cloudflare handles this by serializing the context stack and sending it along with sharded requests, so each server can continue execution with the correct configuration. For tracing, callback capabilities allow different servers to report back without each server having to know where "the collector" lives.
What Cloudflare Got Out Of It
After rolling out worker sharding globally, Cloudflare reported outcomes along these lines:
• Even with low sharding volume, eviction rates dropped significantly, because the long tail of low-traffic Workers stopped churning in and out of memory
• Warm request rate improved from 99.9% to 99.99%, meaning cold starts became 10x less frequent
The theme here is important: the biggest wins didn't come from making startup faster. They came from engineering the system so startup is rarely needed.
Final Thoughts
Cloudflare's worker sharding story is a classic distributed systems lesson dressed up as a performance fix. When a platform scales, the bottleneck often isn't a single slow step, it's how frequently you force that slow step to happen.
By routing each Worker toward a stable "home" server using consistent hashing, Cloudflare turned cold starts from a constant annoyance for low-traffic apps into something that mostly happens once, then disappears into the background.





Comments